Joins
import pandas as pdIn this subchapter, we will go over how to combine different DataFrames in pandas.
To start, let’s load in the same dataset as the first subchapter in the Pandas chapter. As a reminder, this dataset has beer sales across 50 continental states in the US. It is sourced from Salience and Taxation: Theory and Evidence by Chetty, Looney, and Kroft (AER 2009), and it includes 7 columns:
st_name: the state abbreviationyear: the year the data was recordedc_beer: the quantity of beer consumed, in thousands of gallonsbeer_tax: the ad valorem tax, as a percentagebtax_dollars: the excise tax, represented in dollars per case (24 cans) of beerpopulation: the population of the state, in thousandssalestax: the sales tax percentage
df = pd.read_csv('data/beer_tax.csv')
dfHowever, as our purpose is to discuss combining different DataFrames, let us now also load in two additional datasets. The first dataset has the countrywide CPI data for the US, sourced from the Bureau of Labor Statistics. The second dataset has statewide CPI data for some states, sourced from The Slope of the Phillips Curve: Evidence from U.S. States by Jonathon Hazell, Juan Herreño, Emi Nakamura, Jón Steinsson (QJE 2022, link).
us_cpi = pd.read_csv('data/us_cpi.csv')
us_cpi.head()state_cpi = pd.read_csv('data/state_cpi.csv')
state_cpi.head()To join two DataFrames, they must have atleast 1 column that shares the same data, so we can match the different rows appropriately. These columns are often called as foreign keys that map from one table to another. Both the US-wide and statewide CPI tables share the year column with the beer_tax DataFrame, and the statewide CPI table also shares the state column with the beer_tax DataFrame.
First, let’s try joining the US Inflation data with the beer tax DataFrame. We can use pd.merge() to accomplish this. A simple join is done below.
pd.merge(left = df, right = us_inf, left_on = 'year', right_on = 'year')In the pd.merge() function;
the
leftparameter represents one of the DataFrames to combine, this DataFrame is referred to as the ‘left’ DataFrame.the
rightparameter represents the other DataFrame to combine, this DataFrame is referred to as the ‘right’ DataFrame.the
left_onparameter represents the column in the left DataFrame which contains the shared data.the
right_onparameter represents the column in the right DataFrame which contains the shared data.
The left_on and right_on parameters can also take in multiple columns, which comes in handy when we do the merge with statewide inflation data.
mult_col_merge = pd.merge(left = df, right = state_inf, left_on = ['st_name','year'], right_on = ['state','year'])
mult_col_mergeNotice how the output includes both the st_name and state columns. However, these columns are always equal to each other.
(mult_col_merge['st_name'] != mult_col_merge['state']).any()
# We're checking to see if there are any values where the two columns are differentFalseWhile the merges above were useful, they ignored a crucial part of doing merges: the how parameter.
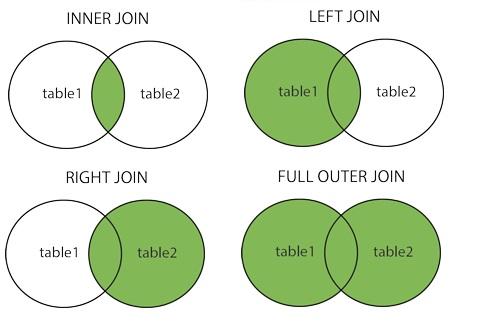
Types of Joins¶
It is very important to understand the four types of join: inner, left, right and outer.
Remember, you are merging two tables on a set of columns. It is possible that one table has a certain value for those shared columns that the other table doesn’t. For example, we have US CPI data from 1967-2023, although our beer dataset only goes from 1970-2003. So, the US CPI DataFrame has several rows which have no match in the beer tax dataframe. The differences between the types of join come from how we deal with these missing values.
An inner join only returns rows where their is a shared value in both tables, it doesn’t allow any
NaN’s to be output in the shared columns. The default join is the inner join, so it is equivalent to the merges we did before.A left join keeps all of the values from the shared column in the left table, even if they do not exist in the right table. For example, the beer tax table contains data on plenty of state/year combinations that the statewide CPI dataset doesn’t contain. Let’s do a left join on these two datasets. To specify which join type we would like to use, we only need to include a
howparameter in ourpd.merge()call.
pd.merge(left = df, right = state_inf, left_on = ['st_name','year'], right_on = ['state','year'], how = 'left')Notice how there are so many NaN values where we have beer data but no state-wide CPI data! As a matter of fact, we’re missing statewide inflation data for over 60% of the state-year combinations in the beer tax dataset.
pd.merge(left = df, right = state_inf, left_on = ['st_name','year'], right_on = ['state','year'], how = 'left')\
['State CPI'].isna().mean()0.6094847775175644Similar to a left join, a right join keeps all of the values from the shared column in the right table, even if they do not exist in the left table. For example, let us do a right join with the US inflation dataset, which has more data than the beer tax dataset.
pd.merge(left = df, right = us_inf, left_on = 'year', right_on = 'year', how = 'right')As expected, we have US inflation data for several years before and after the end of the beer tax dataset, resulting in NaN values for those years!
Finally, an outer join (or full join) keeps all the values from both the tables, regardless of whether or not they exist in the other table. In the example shown below, the beer tax dataset has information on plenty of state-year combinations not present in the statewide dataset, but the statewide dataset has data upto 2017 for some states, while the beer tax dataset ends at 2003 for all states.
pd.merge(left = df, right = state_inf, left_on = ['st_name','year'], right_on = ['state','year'], how = 'outer')Finally, here are a couple of interesting visualizations of the different types of joins.

- Chetty, R., Looney, A., & Kroft, K. (2009). Salience and Taxation: Theory and Evidence. American Economic Review, 99(4), 1145–1177. 10.1257/aer.99.4.1145